
HPDBSCAN – Highly Parallel DBSCAN
Goetz, M., Bodenstein, C., Riedel, M.: HPDBSCAN – Highly Parallel DBSCAN, in conference proceedings of ACM/IEEE International Conference for High Performance Computing, Networking, Storage, and Analysis (SC 2015), Machine Learning in HPC Environments (MLHPC 2015) Workshop, November 15-20, 2015, Austin, Texas, USA
[ EVENT ] [ DOI ] [ JUSER ] [ RESEARCHGATE ]
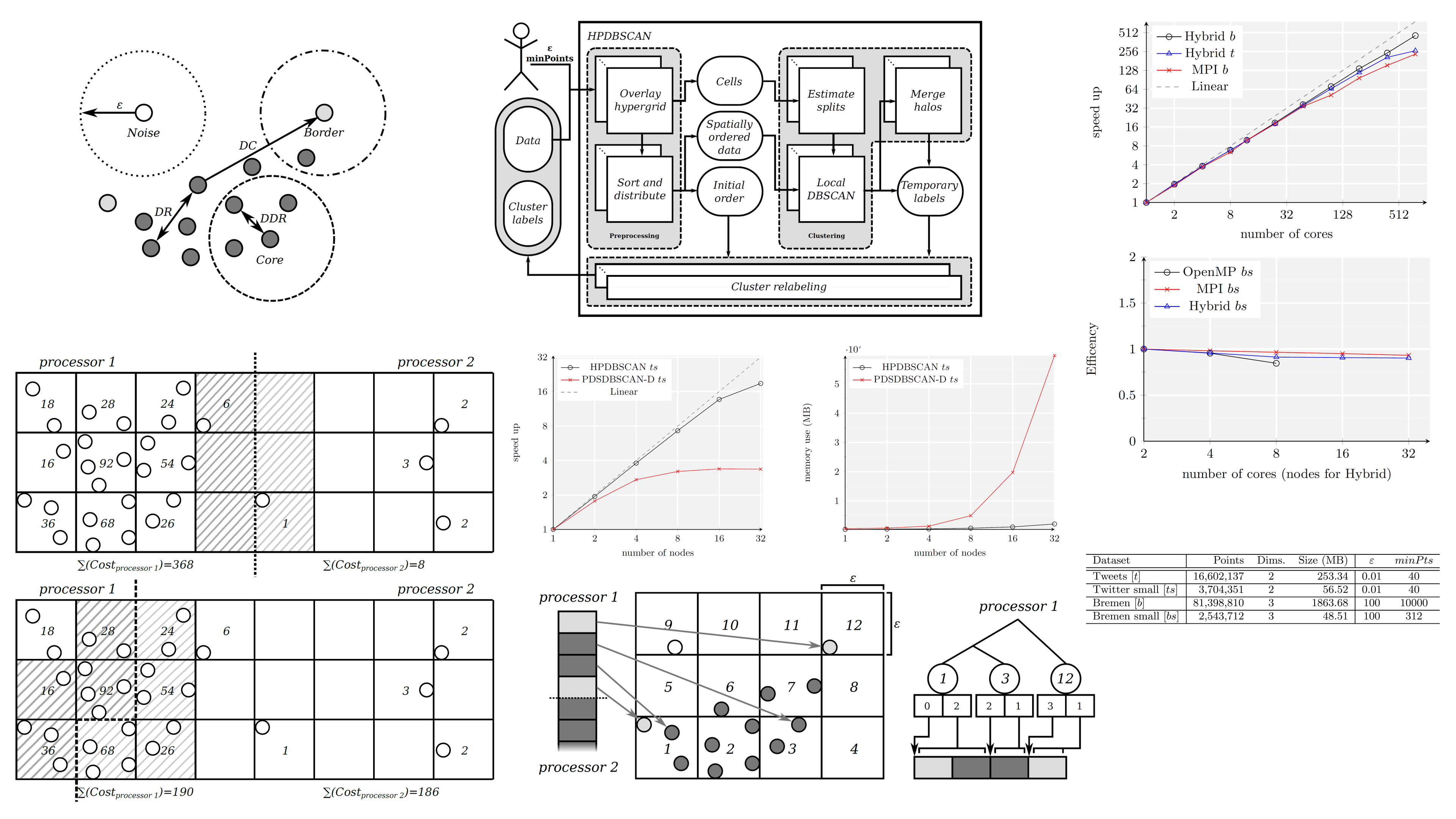
Abstract:
Clustering algorithms in the field of data-mining are used to aggregate similar objects into common groups. One of the best-known of these algorithms is called DBSCAN. Its distinct design enables the search for an apriori unknown number of arbitrarily shaped clusters, and at the same time allows to filter out noise. Due to its sequential formulation, the parallelization of DBSCAN renders a challenge. In this paper we present a new parallel approach which we call HPDBSCAN. It employs three major techniques in order to break the sequentiality, empower workload-balancing as well as speed up neighborhood searches in distributed parallel processing environments i) a computation split heuristic for domain decomposition, ii) a data index preprocessing step and iii) a rule-based cluster merging scheme. As a proof-of-concept we implemented HPDBSCAN as an OpenMP/MPI hybrid application. Using real-world data sets, such as a point cloud from the old town of Bremen, Germany, we demonstrate that our implementation is able to achieve a significant speed-up and scale-up in common HPC setups. Moreover, we compare our approach with previous attempts to parallelize DBSCAN showing an order of magnitude improvement in terms of computation time and memory consumption.
Social Media
@ResearchGate: Well Done Morris! Paper reached 1500 reads: HPDBSCAN Highly #Parallel #DBSCAN #HPC #AI scalable #clustering #algorithm #DataScience #MachineLearning #datamining @DEEPprojects @fzj_jsc @fz_juelich @Haskoli_Islands @helmholtz_ai
.
full text: https://t.co/iUBVwodfHB
. pic.twitter.com/xupDfUbooH— Morris Riedel (@MorrisRiedel) August 18, 2020
ResearchGate: Well Done Morris! Paper reached 1500 reads: HPDBSCAN Highly #Parallel #DBSCAN #HPC #AI scalable…
Posted by Morris Riedel on Tuesday, August 18, 2020
ResearchGate:Good Job Morris!Paper reached 1000 reads: HPDBSCAN Highly #Parallel #DBSCAN #HPC #AI scalable #clustering #algorithm #DataScience #MachineLearning #datamining @DEEPprojects @fzj_jsc @fz_juelich @Haskoli_Islands @helmholtz_ai
.
see full text: https://t.co/iUBVwodfHB
. pic.twitter.com/CsPHNOLOAq— Morris Riedel (@MorrisRiedel) January 5, 2020
ResearchGate:Way to go Morris! Paper reached 20 citations: HPDBSCAN Highly #Parallel #DBSCAN #HPC #AI scalable #clustering #algorithm #DataScience #MachineLearning #datamining @DEEPprojects @fzj_jsc @fz_juelich @Haskoli_Islands @helmholtz_ai
.
Full text: https://t.co/iUBVwodfHB
. pic.twitter.com/rbsyhKo0Gl— Morris Riedel (@MorrisRiedel) December 21, 2019
Researchgate: Good job Morris! Your paper reached 800 reads: HPDBSCAN Highly #Parallel #DBSCAN fast & scalable #clustering #algorithm #DataScience #MachineLearning #datamining @DEEPprojects @fzj_jsc @fz_juelich @Haskoli_Islands @helmholtz_ai
.
Full text: https://t.co/iUBVwodfHB
. pic.twitter.com/cuVFzainNZ— Morris Riedel (@MorrisRiedel) November 1, 2019
Researchgate: Great Work, Morris! Your paper reached 700 reads: HPDBSCAN Highly #Parallel #DBSCAN fast & scalable #clustering #algorithm #DataScience #MachineLearning #datamining @DEEPprojects @fzj_jsc @fz_juelich @Haskoli_Islands @helmholtz_ai
Full text: https://t.co/iUBVwodfHB pic.twitter.com/QAOv9T0FhC
— Morris Riedel (@MorrisRiedel) September 15, 2019
ResearchGate: Nice work, Morris! Your research items reached 6000 reads: most read paper ~600 reads is HPDBSCAN: highly parallel DBSCAN @ SC2015 & used in #MachineLearning #datamining @DEEPprojects @fzj_jsc @fz_juelich @Haskoli_Islands #SMITH
full text: https://t.co/72Ek7SPDK5 pic.twitter.com/TY8L2zuPXj
— Morris Riedel (@MorrisRiedel) July 5, 2019
 https://orcid.org/0000-0003-1810-9330
https://orcid.org/0000-0003-1810-9330